Why the CFPB should encourage the use of AI in underwriting

The Bureau of Consumer Financial Protection (CFPB) issued a call for comment earlier this year to identify opportunities to prevent credit discrimination, encourage responsible innovation, promote fair, equitable, and nondiscriminatory access to credit, address potential regulatory uncertainty, and develop viable solutions to regulatory compliance challenges under the Equal Credit Opportunity Act (ECOA) and its implementation through Regulation B.
Zest AI, along with more than 140 other interested parties, submitted views about how to achieve these important goals. A lightly edited version of our comment letter is below. If you want the original letter we submitted, it’s here.
The tl;dr? We believe AI and machine learning-based credit models offer the best chance to end racial disparities in consumer finance while improving the safety and soundness of U.S. financial institutions. The CFPB should continue to encourage the responsible use of AI and ML in underwriting consumer loans to increase access to credit for people of color, immigrants, and other disadvantaged groups. Also, lenders who use ML models should be required to use rigorous math to identify principal denial reasons or they will inevitably mislead consumers.
———————————————————————————
Re: Request for Information on the Equal Credit Opportunity Act and Regulation B by the Consumer Financial Protection Bureau (Docket No. CFPB-2020-0026)
Dear Director Kraninger:
Zest AI appreciates the opportunity to comment on the CFPB’s request for information on the Equal Credit Opportunity Act and Regulation B, particularly on disparate impact in lending and the use of artificial intelligence and machine learning. We believe that AI/ML, when appropriately used, hold the keys to ending racial disparities in consumer financial services while at the same time improving the safety and soundness of American financial institutions.
This spring and summer sparked historic awareness of racial injustice and disparities in the United States. We applaud the CFPB for joining that conversation and taking steps to “create real and sustainable changes in our financial system so that African Americans and other minorities have equal opportunities to build wealth and close the economic divide.”1 As the CFPB has recognized, ECOA can be a powerful tool. Still, it must be “interpret[ed] and appl[ied] . . . to achieve the goals of fair lending, including preventing credit discrimination and expanding access to credit.”
Zest AI shares that mission. We exist to make fair and transparent credit available to everyone. Banks, credit unions, and other mainstream financial institutions use our ML-powered underwriting technology to make more loans to more people, including people of color, without increasing default risk. The Federal Home Loan Mortgage Corporation (“Freddie Mac”) recently announced its partnership with Zest AI to help make the dream of homeownership a reality for tens of thousands of minority borrowers in the coming years.
The responsible use of explainable ML-powered underwriting models for consumer loans and mortgages offers a practical way to break the cycle of credit discrimination in America. If the Bureau encourages lenders to run thorough searches for less discriminatory alternative models, lending decisions will become less biased against people of color and other historically marginalized groups. Also, if the Bureau revises guidance to require the use of more accurate and mathematically-justified methods to generate adverse action notices, consumers will get more precise information when they are denied credit. The methodologies and technologies we commend here are available to lenders today, and not just from our company. We encourage the Bureau to promote their use to end unfair discrimination in consumer lending in America.
Most lenders and consumers want to see equal access to credit for people of color and other historically marginalized groups. In a recent Harris Poll, we learned that seven out of ten consumers said that they would change financial institutions to one that had more inclusive lending practices.4 Most of our customers choose to use our ML-powered underwriting technology, in part, because it is fairer to people of color. ML underwriting is the only way we’ve found to accurately identify creditworthy people of color who are being unfairly denied credit, especially those who have thin or no credit files.
Zest AI’s Mission is to Bring the Benefits of ML Underwriting to the World of Consumer Financial Services—to Make Fair and Transparent Credit Available to Everyone
At Zest AI, we have spent the last decade becoming the leader in creating technology to enable lenders to use AI and ML models for credit underwriting. We help lenders compliantly build, adopt, and operate those models for a wide range of mainstream credit products, including credit card, auto, student, and mortgage loans. By taking a math-based and measurable approach to underwriting, Zest AI’s tools allow lenders to approve more good borrowers without adding risk while ensuring maximum fairness in loan decisioning.
Lenders regularly use our software and modeling capabilities to safely increase loan approval rates, lower defaults, and make their lending fairer. Our tools allow lenders to explain, validate, interpret, and document the reasoning behind their credit decisions. Zest AI ML models are also wholly explainable – no matter the complexity of the model or the number of data inputs, Zest AI can measure and express the mathematical contributions or influence of each input feature towards the model’s prediction.
Given the ability to measure and quantify the import of model inputs, Zest AI has also developed methodologies that allow lenders to quickly identify disparate impact in their models and generate less-discriminatory alternatives that still serve their business interests. These methodologies do not impose material burdens on lenders; instead, they enable lenders to reduce disparities while making, in the words of the Supreme Court, “the practical business choices and profit-related decisions that sustain a vibrant and dynamic free-enterprise system.”
Despite decades of effort, many lenders have struggled to develop underwriting models that balance the need to accurately predict the risk of default with the need to minimize disparate impact. Zest AI has perfected a technique that allows lenders to do just that by modifying their underwriting models to cause less disparate impact with only minimal impact on accuracy. That is, we have developed a modeling technique that helps lenders optimize their underwriting models for both accuracy and fairness.
The CFPB Should Continue to Encourage the Responsible Use of AI and ML in Underwriting Consumer Loans to Increase Access to Credit for People of Color, Immigrants, and Other Disadvantaged Groups
If you’ve ever played with the bass and treble settings on your stereo, you can understand the process. If you turn the bass all the way up and the treble all the way down, you get only the bass; you have optimized for bass. But, if you turn both bass and treble up, they end up canceling each other out to some extent, so you’ve only achieved the same thing as turning both knobs up part-way. Double optimization works the same way in underwriting models, except fairness and accuracy are the knobs instead of bass and treble.
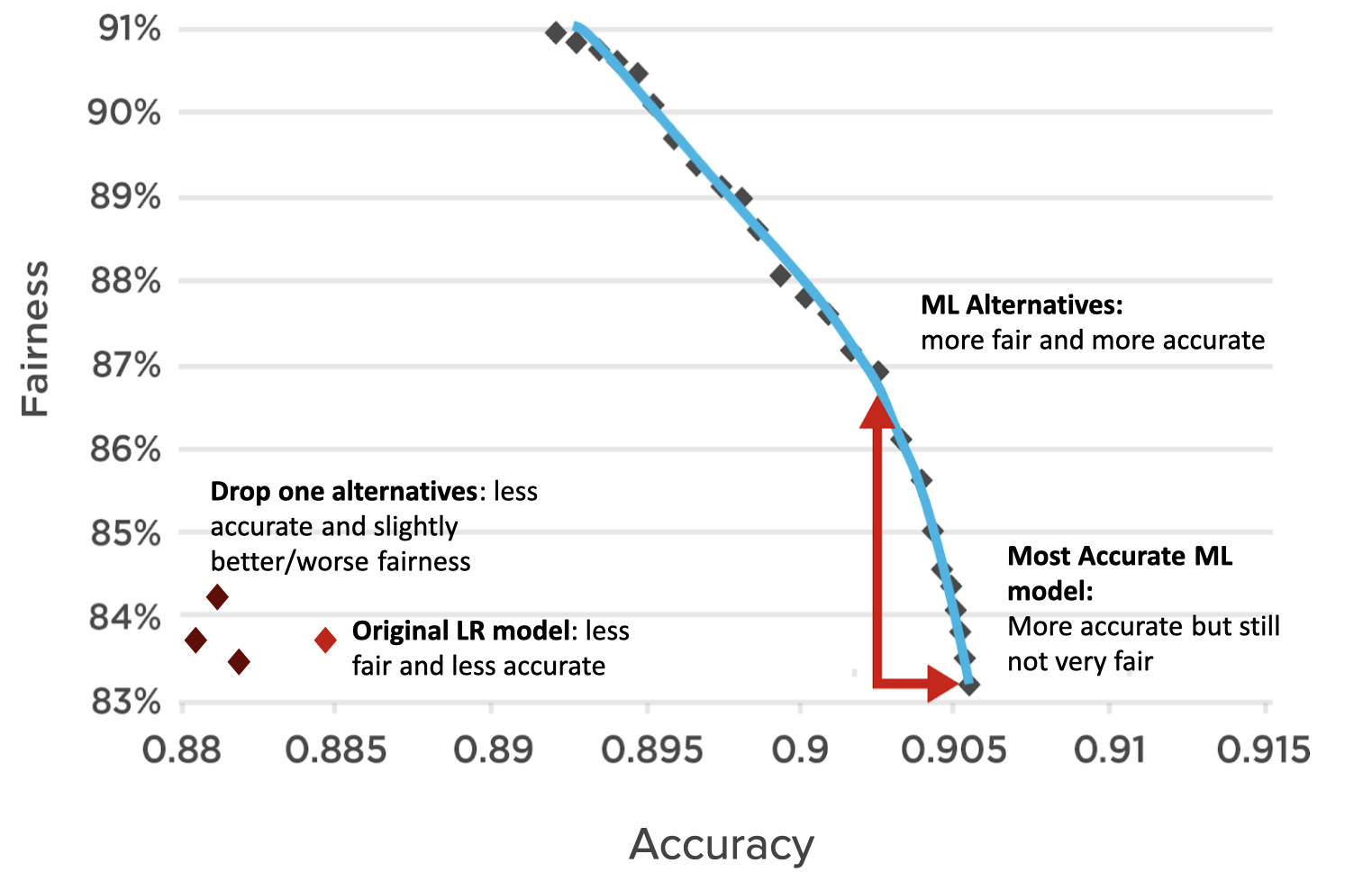
The graph above shows what happens when you double-optimize lending models using standard logistic regression (“LR”) approaches versus ML techniques. The y-axis represents fairness, measured by the Adverse Impact Ratio (“AIR”). The x-axis represents the underwriting decision’s accuracy, measured by the area under the curve (“AUC”). Every diamond is a different model. The diamonds along the blue line are various ML models tuned for accuracy and fairness in different proportions. These models are all very close to one another, meaning that the trade-off between accuracy and fairness is relatively small. Contrast the blue line to the diamonds on the left, representing a lender’s attempts to use “drop one” methods (explained more fully below) to create fairer alternatives to the original LR model. What you see is that the lender has to give up a lot of accuracy to make the model only marginally fairer.
Notably, lenders can achieve these gains without considering protected status as an input in underwriting. Instead, they consider fairness during model creation, modifying the model’s loss function to incorporate fairness as a model objective. This process results in a fairer model without violating ECOA or Reg. B’s prohibition on disparate treatment. Lenders can choose the extent to which fairness enters into the process, develop many alternative models, and select one for use in production.
The above graph illustrates what we typically see when we use the technique across many different loan products and portfolio sizes. What these results show is that the double-optimization of ML models gives lenders better alternative models from which to choose. Some lenders may select the most accurate ML model. When presented with the choice, many lenders we work with are selecting models that cause less disparate impact.
The legal landscape, however, is such that some lenders may be afraid to use this technology. They don’t want to face liability for choosing one model on the curve over another. We believe that such fears are unfounded. A bank can conduct these analyses under legally privileged conditions, and for years these risks have not dissuaded major lenders from using other ways of identifying and choosing between less discriminatory alternatives.
Nevertheless, we believe that Bureau guidance can encourage lenders to run rigorous searches for less discriminatory alternative models using dual optimization modeling techniques. The guidance should also specify that the Bureau will not penalize lenders for choosing a less biased alternative model over another, so long as the selected model is less accurate than the most accurate model reasonably available and has a lower adverse impact ratio for protected groups in the aggregate than the most accurate model reasonably available. Such guidance would pave the way for a significant leap forward in fair lending by encouraging lenders to make sensible trade-offs between accuracy and fairness to help protected groups gain access to credit.
Of course, even when models have been optimized for fairness and accuracy, some consumers will be denied credit. Providing these consumers with accurate information about why they may have been denied is critically important; it is the only way for them to know what behavior to change or what questions to ask in correcting errors in their credit profile. What is less obvious, however, is that identifying principal denial reasons requires advanced math whether a lender uses an ML model or a logistic regression underwriting model, though, as we explain, the need is far more significant for ML models.
Requiring Lenders Who Employ ML Models to Use Rigorous Math to Identify Principal Denial Reasons is Essential to Avoid Misleading Consumers and Making Bad Policy
Some lenders use one of two seemingly reasonable methods to identify the principal reasons that their ML and LR models denied a credit application: “drop one” and its cousin “impute median.” With drop one, lenders test which model variables contribute most to the model score by removing one variable from the model and measuring the change in the score as a means of quantifying the importance or influence of the removed variable. With impute median, lenders do the same thing but, instead of dropping a variable, they replace each variable, one at a time, with the median value of that variable in the dataset.
As we said, those methods sound reasonable. They essentially say, let’s see whether so and so would have been denied if they didn’t have X variable in their credit file or if their X variable were the same as everyone else’s. But, in practice, those methods are often inaccurate for at least two reasons. First, once you change the data that the model considers, you have moved from the real world into a hypothetical one. You end up trying to explain situations that would never happen in the real world, such as where the income variable is missing (because it was kicked-out during the drop one analysis), but the debt-to-income ratio is available. This situation is impossible in reality, and so is the resulting explanation.
Second, those methods produce wrong principal reasons when used to explain ML and even LR underwriting models because they don’t account for variable interaction. Variables are not always independent and, in ML models, may point in different directions. Of course, LR models are largely blind to variable interactions, making the drop one and impute median methods more accurate when applied to LR models (at least, in the experiments we have conducted). But ML models rely, in part, on modeling interactions between variables to gain predictive power, meaning that drop one and impute median identify the wrong denial reasons almost every time when used on ML models.
While participating in the CFPB’s October Tech Sprint on improvements to adverse action notices, we ran an experiment on an auto lending ML model and dataset from one Florida lender. Our test showed that the drop-one method identified the correct principal reason code only 11% of the time, while the impute median approach was almost always wrong. We’ve seen similar results in our work for dozens of financial institutions.
When we explain this, we are often asked, “But how can any math equation accurately capture and explain the interaction of so many variables? And how can we know with certainty that such an equation is accurately identifying the most important factors influencing the model’s decision?”
The answer is simple: the mathematics of games. In the 1960s and ’70s, certain mathematicians, sociologists, and economists became interested in what has come to be called “game theory.” Those mathematicians started trying to quantify how each player on a sports team contributed to the final score of the game, taking into account the number of baskets, touchdowns, or goals the player scored and the player’s assists, passes, and blocks. Game theory pioneer Lloyd Shapley eventually won the Nobel Prize in Economics because of this work. It turns out that the mathematical tools and proofs that Shapley developed are the best way to explain how ML models make decisions. In the case of an ML model, the “players” are the model variables, the “game” is the model, and the “score” is the model’s output (in credit, this usually represents the probability of defaulting on a loan). That’s why applying game theory math to ML models works so well.
ECOA and Reg. B require lenders to provide the principal reasons for denying a credit application. To do so, lenders must quantify the importance of a variable in the model to determine whether the reason is more or less important than other potential reasons. Shapley’s method precisely quantifies the significance of model variables in generating a given score for a given applicant. It also considers variable interactions so we can know exactly how much each variable contributed to the credit decision. Shapley proved his method is the only reasonable way of assigning credit in games of this sort. We have used Shapley’s approach (and its formal extensions) to explain millions of ML lending decisions for many different kinds of models throughout our history as a company.
We believe game-theoretic approaches to explainability are not only entirely consistent with ECOA, Reg. B, and existing Bureau guidance, but also the most effective way to ensure compliance. They accurately identify principal denial reasons every time. Nonetheless, we believe that updating Bureau guidance to reflect the acceptance of these explainability methods would speed adoption, increase the accuracy of the information that consumers receive, and provide policymakers with better information about why particular consumers are denied credit. We encourage the Bureau to adopt formal guidance requiring the use of rigorous game-theoretic mathematical methods to explain decisions made by ML and LR models to provide the correct principal denial reasons in consumer notices.
The CFPB should continue to encourage lenders to embrace rigorous explainability and fair lending techniques as a central part of AI development and implementation in consumer lending and take further steps to clarify the Bureau’s support of such efforts. These efforts will increase underwriting decisions’ accuracy, drive increased access to fair credit, enhance compliance with fair lending requirements, and facilitate further innovation.
Conclusion
The CFPB should continue to encourage lenders to embrace rigorous explainability and fair lending techniques as a central part of AI development and implementation in consumer lending and take further steps to clarify the Bureau’s support of such efforts. These efforts will increase underwriting decisions’ accuracy, drive increased access to fair credit, enhance compliance with fair lending requirements, and facilitate further innovation.

